


Il est rare que je fasse de la pub pour un site mais là franchement, depuis ce début d’année j’ai changé ma manière de créer des slides en utilisant le site web : slides.com. Il permet d’éditer très facilement ses diaporamas en ligne avec du html et du css pour un rendu moderne et sexy grâce à la palette de styles proposés. Sous le capot, ça utilise la librairie opensource reveal.js. Et pour tout vous dire, je ne retournerai pas pour 3 bitcoins sous libreoffice pour créer mes futures slides. Seul hic…
[edit : 06.03.25] Le site slides.com a mis en place des protections pour empêcher la récupération des diaporamas en pdf. Elles sont néanmoins contournables . Mais j’ai décidé de ne pas jouer au chat et la souris et de ne pas poursuivre le partage d’astuces sur ce sujet précis.[/edit]

Slides.com gratuit mais …
Seule ombre à ce tableau, c’est que slides.com permet uniquement de sauvegarder ses slides en html et pas en pdf. Tu me diras c’est pas grave il existe des outils libres sous linux qui permettent de convertir du html en pdf facilement : wkhtmltopdf par exemple ou encore à l’ancienne ,d’enregistrer au format pdf avec l’imprimante de son navigateur firefox…
A ça tu rajoutes , le fait que le diaporama que tu auras téléchargé en html ne récupère pas les styles , les polices, les images en local. Elles sont toutes hébergées sur des serveurs distants. Le fichier html récupéré contient donc une multitude d’url qui pointent vers des serveurs externes type amazon.
Pour tester, si tu t’amuses à lancer le fichier html de tes slides à partir de ton pc sans internet tu verras que ton diaporama tire une sale tronche. Il n’arrive pas à charger les images , les polices, les styles… Dès lors je me suis posé la question de comment faire pour récupérer toutes les slides et leurs ressources sur mon pc sans payer 🙂
Voici la recette que je te partage dans ce billet :
1- Télécharger en html ses slides
Sur https://slides.com , aller dans la barre de menu latérale gauche :
- choisir « export »
- Download HTML
2 – Récupérer les images et le style css en local
Le fichier html téléchargé en local a son style, ses polices et ses images hébergés sur des sites externes.
Le script bash suivant que je me suis amusé à faire, permet de tout télécharger, de sauvegarder en local sur son pc et de lire hors ligne les diaporamas générés sur slides.com.
Ça se passe en 2 temps :
- télécharge toutes les images , polices et css dans un dossier nommé « ress »
- édite le fichier html pour remplacer les url externes par des liens qui pointent vers les ressources locales
#!/bin/bash
# script pour télécharger html
# Vérifier si un argument est passé
if [ $# -eq 0 ]; then
echo "Usage: $0 <nom_du_fichier.html>"
exit 1
fi
dossier="ress"
rm -rf "$dossier"
# Créer un dossier pour stocker les ressources
if [ ! -d "$dossier" ] ; then
mkdir -p $dossier
fi
file_html=$1
#file_html="slides-copy-of-mastodon-24-02.html"
# Vérifier si le fichier existe
if [ ! -f "$file_html" ]; then
echo "Le fichier $file_html n'existe pas."
exit 1
fi
# Utiliser grep pour extraire les URLs des images PNG, GIF, JPG, JPEG et des fichiers CSS
resource_urls=$(grep -oE 'src="([^"]+\.(png|gif|jpg|jpeg))"|href="([^"]+\.css)"|https://[^"]+\.css|url\("https://[^"]+\.css' $file_html | awk -F'"' '{print $2}')
# matcher les thumbnails
#https://s3.amazonaws.com/media-p.slid.es/thumbnails/555be4151bda1232ff45e5088cf920ae/thumb.jpg?1708767330
# Boucle pour télécharger chaque ressource et les placer dans le dossier "ress"
for url in $resource_urls; do
# Extraire le chemin du serveur distant (à l'exclusion du nom du fichier)
server_path=$(dirname "${url#*//}")
# Créer la structure de dossier dans "ress" en utilisant le chemin du serveur
mkdir -p "$dossier/$server_path"
# Télécharger la ressource et la placer dans la structure de dossier correspondante
wget "$url" -P "$dossier/$server_path"
done
# Copier le fichier HTML d'origine vers un nouveau fichier
cp $file_html output.html
# Remplacer les URLs des ressources par des chemins relatifs dans le fichier de sortie
for url in $resource_urls; do
file_name=$(basename "$url")
server_path=$(dirname "${url#*//}")
# Remplacer l'URL par un chemin relatif
sed -i "s|$url|$dossier/$server_path/$file_name|g" output.html
done
echo "Le téléchargement des ressources est terminé. Les ressources sont classées dans le dossier 'ress'. Le fichier HTML modifié est 'output.html'."
3 – Convertir html en pdf
tout en gardant le style et la mise en page:
– suffit de rajouter à la fin de l’url : « ?print-pdf«
(Merci la doc de reveal.js)
exemple lorsque tu lances ton fichier html avec firefox:
http://output.html?print-pdf
puis tu choisis d’imprimer en choisissant « enregistrer au format pdf » avec son navigateur favori :
Ne pas oublier aussi de cocher dans les options d’impression :
« imprimer les arrières plans »
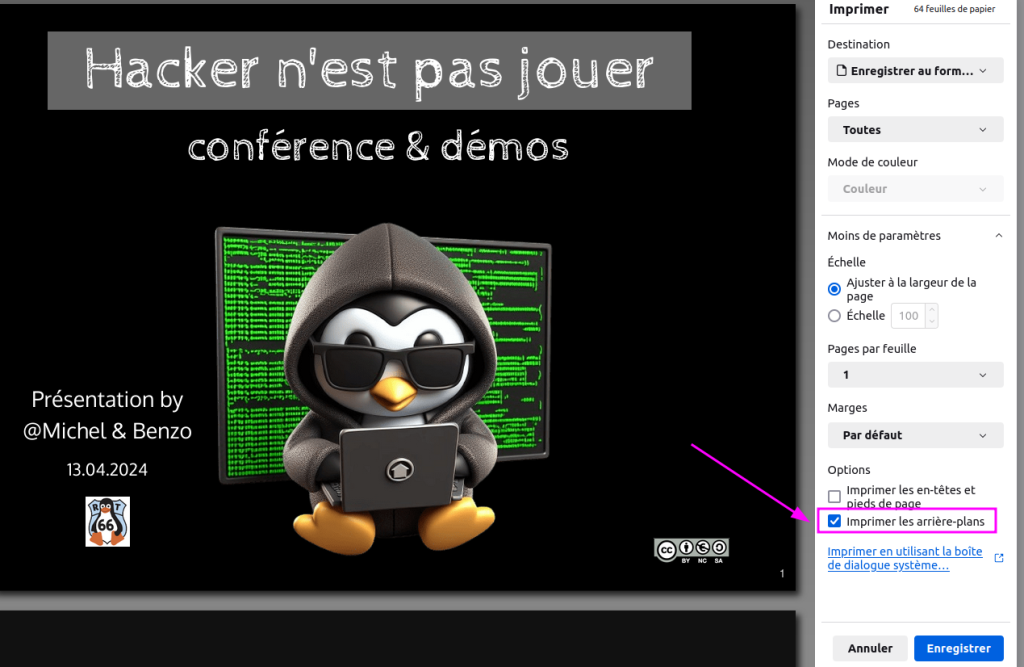
Et voilà en cliquant sur enregistrer, tu obtiens un joli pdf , fidèle aux slides du site !
Merci pour l’astuce.